Fuzzy matching, but for concepts
There's a special kind of despair that comes with staring at two datasets that should obviously connect, but refuse to play nice. You know they belong together but no fuzzy matching technique can help you. It's a concept that you wanna match. Zero-shooting can be the solution.

A database is only as powerful as its capacity to connect with another one. Ask any data journalist about their best stories, and they’ll probably trace them back to a successful =VLOOKUP() or a clean left_join() that suddenly made two disparate datasets give them answers (or new questions). It’s why one of the first things we do is hunt for recognizable key patterns in any database—that usually means there’s data to add to it.
At PÚBLICO, nobody gets quite as excited about finding a column named “dicofre”—the code Portugal’s statistical institute gives to every piece of land in the country—as our data team does. It’s like finding the perfect LEGO piece; if it exists, it means I can snap another piece onto it.
But dreams can quickly become nightmares. Dirty columns and the million creative ways humans find to spell the same thing can turn what should be a simple join into a data journalist’s worst nightmare—usually meaning days of manual cleaning, character by character, row by row. That’s where fuzzy matching becomes our salvation: algorithms that can somehow recognize that “PT,” “Portugal,” and “POR” all mean the same “thing.”
There are many great ways to do it. Max Harlow, a data journalist at Bloomberg and regular speaker at Dataharvest, has, for example, CSV Match for this. I highly recommend checking out his materials [here](https://docs.google.com/presentation/d/1XvU_ooWQLLWvK88ehVIBcQqiaqpwxDHXNkkqZ9kVS_8/edit?slide=id.g2bd4db8ec7e_0_146#slide=id.g2bd4db8ec7e_0_146](https://docs.google.com/presentation/d/1XvU_ooWQLLWvK88ehVIBcQqiaqpwxDHXNkkqZ9kVS_8/edit?slide=id.g2bd4db8ec7e_0_146#slide=id.g2bd4db8ec7e_0_146).
But recently, I faced something more… abstract: What happens when you need fuzzy matching not just for messy text, but for concepts?
Matching concepts: an example
Let me paint the picture with the specific challenge that landed on my desk:
Portuguese universities offer roughly 1,500 uniquely named degree programs, ranging from “Communication Sciences” to “Civil Engineering.” Meanwhile, the U.S. Department of Labor maintains O*NET, a database of about 900 professional occupations, each scored on Holland’s RIASEC personality framework—basically, a way to map careers to personality types.
Now, I’m generally skeptical of the idea that every college degree should funnel you toward a single profession. Education is richer and more complex than that. But statistically speaking, there are clear patterns: someone graduating with a degree in Statistics is more likely to work as a statistician than as a barber. (Though if you’re a statistician-barber, please email me—I’d love to hear that story.)
Traditional fuzzy matching tricks would catch some connections: “Applied Statistics” and “Statistician” share obvious similarity. But what about my own degree? “Communication Sciences” typically leads to careers in journalism, PR, advertising, or multimedia work—conceptual connections that no amount of string similarity could detect.
We needed to bridge these databases, essentially giving every Portuguese degree a personality score. It was fuzzy matching, but for concepts.
The solution we landed on was treating this as a zero-shot classification problem.
Zero-shooting the problem
If you’ve used any kind of LLM, you might have noticed their ability to make “connections” about ideas. Somewhere in that multi-dimensional matrix of a model, concepts are encoded so that the model knows someone with a degree in Gerontology will likely work as a Social Worker or Nursing Home Administrator.
Of course, we could simply use an OpenAI API and prompt it to loop through the database with something like:
Given the following list of 900 professions, which of them could be done with a degree in [name_of_degree]It would probably work somewhat fine. But if you’ve ever done something like this, you know what comes next:
- Prompt engineering and endless tweaking through trial and error
- Hallucination checking
- Answers that aren’t quite in the format you need (LLMs love a good “here is a list of…”). Lovely when you’re chatting; not so good in a dataframe.
- An expensive bill
You might have heard this elsewhere, but I’ll say it again: you don’t always need bleeding-edge expensive models for your task.
That’s where zero-shot classification comes in. It’s doable with models of 100M+ parameters. HuggingFace summarizes it perfectly in this image:
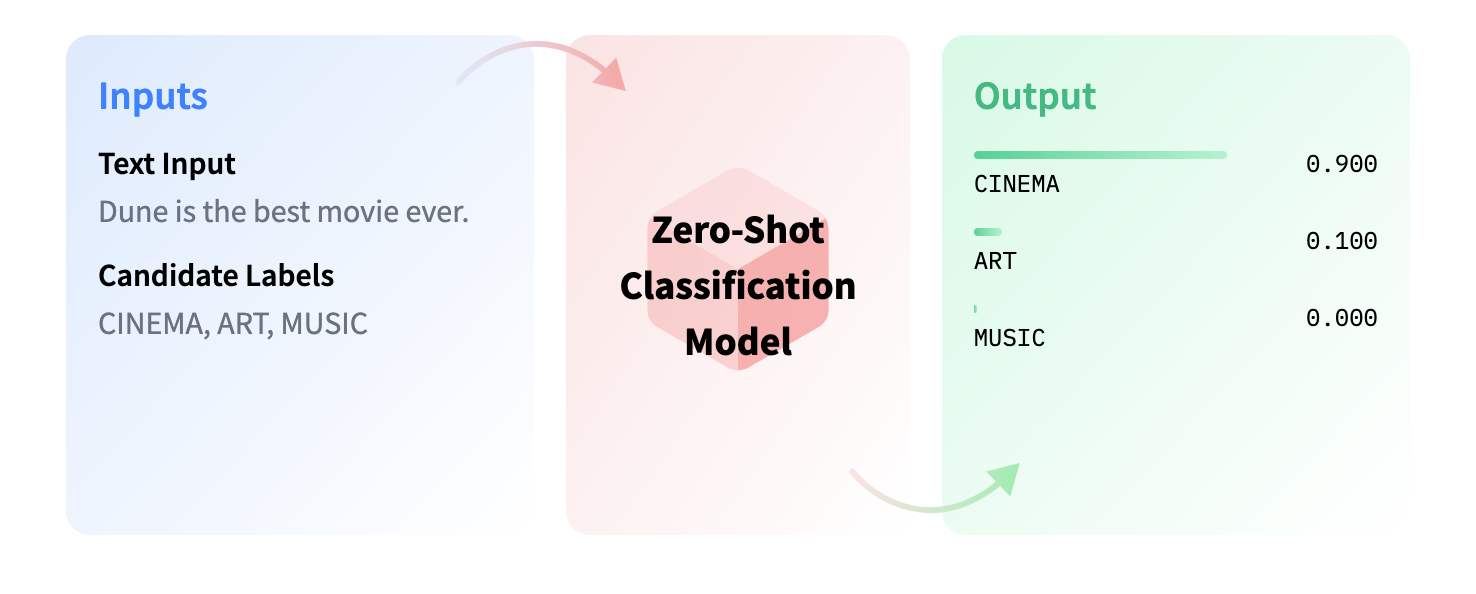
🤗 Transformers
HuggingFace’s transformers library in Python is a blessing for tasks like this. All you have to do is import the library, specify the model you want to use, the text you want to classify (in our case, we used the degree name plus the category where the Portuguese higher education system has placed that degree), and the candidate labels (each of the 900 professions).
Something as simple as this:
from transformers import pipeline
pipe = pipeline(model="facebook/bart-large-mnli")
pipe("Communication Sciences",
candidate_labels=["Social Worker", "Nurse", "Civil Engineer", "Journalist", "Data Scientist" ...],
)For each degree, we got a 0 to 1 confidence value for every candidate label.
Well, the rest is easy: make it a loop and save the results.
Caveats
Of course, things are never this simple in real life, right? I think it’s worth mentioning the problems we faced:
- Since one course can lead to multiple professions, this is actually a case where each candidate label is “tested” individually. Which means that for a single course, we would end up getting 1,350,000 labels. But obviously, just a tiny fraction of those are relevant. We ended up selecting the top 10 highest-scored labels…
- …because we knew we would need to do manual checking anyway. But it’s always easier to check a robot’s work than do it yourself from scratch.
- Because we were in a rush, there wasn’t much time to test different models. We ended up going with “mDeBERTa-v3-base-xnli-multilingual-nli-2mil7” because it was mentioned online as a good model for multilingual tasks. Our labels were in English; our degree names and descriptions were in Portuguese.
- It was hilarious to see some of the crazy relationships the model made. A degree in “Línguas Aplicadas” (Applied Languages) ended up being classified as best suited for someone who wants to become a dentist (because “língua” means “tongue” in Portuguese). I mean, you can see where that came from 🤷♂️.
- Running locally doesn’t always mean free. Because my poor 2019 MacBook can’t handle much these days, I ended up renting an RTX 4090 on vast.ai. If you’ve never run a script outside your laptop, doing it while knowing you’re being charged $0.249/hour can be nerve-wracking. Though maybe it was overkill for this task. Maybe it’s a Mac user/non-gamer problem, but I hate having to pick a graphics card to rent without knowing if I’m choosing the right one for the job.
And, if got curious, you might want to check the end result here.

About Rui Barros
Data journalist at PÚBLICO working with APIs, machine learning, and data analysis. I write about computational journalism techniques and tools.